Як Гугл боти обробляють JS?
Розуміння того, як пошукові системи вивчають, рендерують та індексують веб-сторінки, має вирішальне значення для оптимізації сайтів під пошукові системи. У міру змін у роботі пошукових систем (наприклад, Google), як Гугл боти обробляють JS?, що працює, а що ні, стає все складніше, особливо у випадку з клієнтським JS.

Все ще існують застарілі переконання, які вводять в оману SEO-фахівців щодо вибору найкращих рішень для пошукової оптимізації додатків:
- Google не вміє рендерувати клієнтський JS.
- Google по-різному обробляє сторінки JS.
- Черга рендерингу та його тривалість значно впливають на SEO.
- Сайти з великим обсягом JS повільніше індексуються.
Щоб розібратися з цими переконаннями, ми об'єдналися з MERJ, провідною консалтинговою компанією в галузі SEO та управління даними, та провели експерименти з вивчення поведінки пошукового робота Google. Ми проаналізували понад 100 000 запитів Googlebot на різних сайтах, щоб протестувати та підтвердити (або спростувати) його можливості, пов'язані з SEO.
Розгляньмо, як еволюціонував рендеринг Google. Потім проаналізуємо наші висновки щодо реального впливу клієнтського JS на сучасні веб-програми.
❯ Еволюція можливостей рендерингу Google
За минулі роки здатність Google вивчати та індексувати веб-контент зазнала значних змін. Розуміння цих змін є важливим для усвідомлення поточного стану SEO для сучасних веб-додатків.
До 2009 року: обмежена підтримка JS
На зорі пошукових систем Google в основному індексував статичний HTML-контент. Контент, створений за допомогою JS, був майже невидимим для пошукових систем, що призводило до необхідності використання статичного HTML.
2009-2015: схема AJAX-індексації
Google створив схему AJAX-індексації (AJAX crawling scheme), що дозволяє сайтам надавати HTML-знімки (HTML snapshots) контенту, що динамічно генерується. Це було тимчасовим рішенням, що вимагає від розробників створення окремих версій веб-сторінок, що піддаються індексації.
2015–2018: початок виконання JS
Google почав рендерувати сторінки за допомогою браузера Chrome без графічного інтерфейсу. Значний крок уперед. Однак стара версія браузера була обмежена у обробці сучасних можливостей JS.
2018-тепер: сучасні можливості рендерингу
На даний момент Google використовує сучасну версію Chrome для рендерингу веб-сторінок. Ключові аспекти поточної системи включають:
Актуальний браузер Googlebot використовує останню стабільну версію Chrome/Chromium, що підтримує сучасні можливості JS.
Рендеринг без збереження стану: кожен рендеринг сторінки відбувається у новій сесії браузера, без збереження куки чи станів попередніх рендерингів. Зазвичай Google не натискає на елементи на сторінці, такі як вкладки або банери cookie.
Екранування: Google забороняє показувати різний контент користувачам та пошуковим системам, щоб маніпулювати рейтингами. Уникайте коду, який змінює вміст на основі User-Agent (пристрою користувача). Натомість оптимізуйте програму на основі рендерингу без збереження стану для Google та реалізуйте персоналізацію за допомогою методів зі збереженням стану.
Кешування ресурсів: Google прискорює рендеринг веб-сторінок за рахунок кешування ресурсів, що практично для сторінок, що використовують спільні ресурси, і для повторного рендерингу однієї сторінки. Замість використання заголовків HTTP Cache-Control служба рендерингу веб-сайту Google використовує власні внутрішні евристики для визначення, коли кешовані ресурси залишаються актуальними, а коли їх необхідно оновити.
Сучасний процес індексації Google виглядає приблизно так.
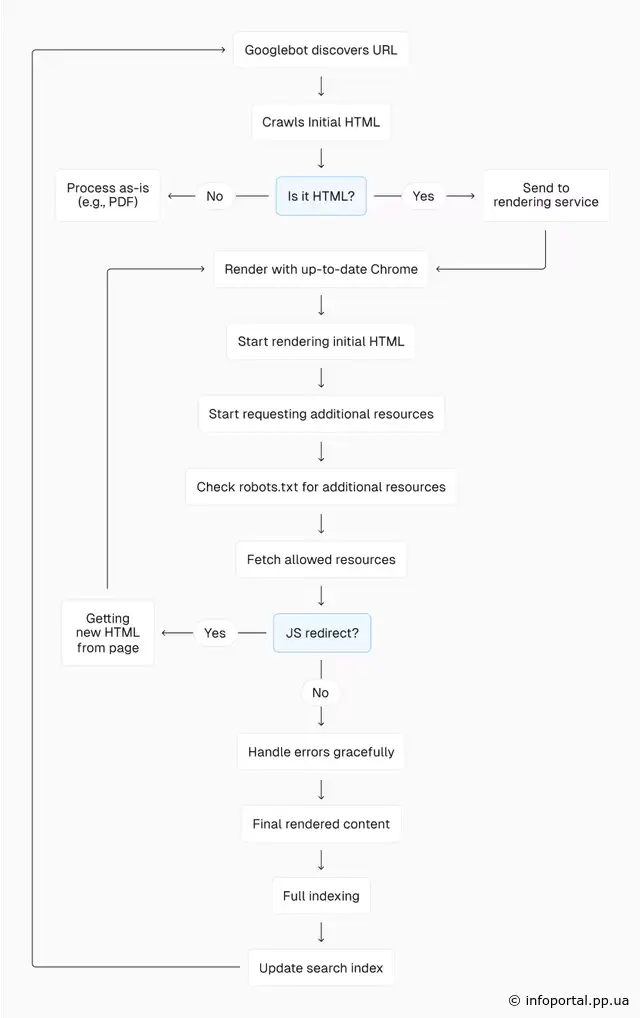
Тепер коли ми краще розуміємо можливості Google, пов'язані з SEO, розглянемо деякі поширені міфи.
❯ Методологія
Для перевірки найпоширеніших міфів ми провели дослідження, використовуючи інфраструктуру Vercel та технологію Web Rendering Monitor (WRM) від MERJ. Наш фокус був зосереджений на сайті nextjs.org з додатковими даними monogram.io і basement.io, що охоплюють період з 1 по 30 квітня 2024 року.
Збір даних
На зазначені сайти було впроваджено спеціальний проміжний шар (Edge Middleware), щоб перехоплювати та аналізувати запити від пошукових ботів. Цей шар дозволив:
Виявляти та відстежувати запити від різних пошукових систем та AI-агентів (при цьому жодні дані користувача не використовувалися).
Вбудовувати легковажну JS-бібліотеку в HTML-відповіді для роботів.
Ця бібліотека, спрацьовуючи після завершення рендерингу сторінки, надсилала на спеціальний сервер таку інформацію:
URL сторінки
унікальний ідентифікатор запиту (для порівняння із серверними логами)
тимчасову відмітку завершення рендерингу (розраховувалася на основі часу отримання запиту бібліотекою на сервері)
Аналіз даних
Зіставивши інформацію із серверних логів про початкові запити з даними, отриманими від посередника, ми змогли:
Визначити, які сторінки були успішно відрендеровані пошуковими системами.
Розрахувати час між початковим аналізом та завершенням рендерингу.
Виявити особливості обробки різного типу контенту та URL-адрес.
Обсяг даних
Основна увага була приділена даними, отриманими від Googlebot, оскільки це забезпечило нам найбільшу та надійну базу. Аналіз охопив понад 37 000 відрендерених HTML-сторінок, що дозволило сформувати міцну основу для подальших висновків.
Ми також продовжуємо збирання інформації про обробку контенту іншими пошуковими системами, включаючи AI-агенти на зразок OpenAI та Anthropic, та плануємо поділитися цими результатами в майбутньому.
Далі ми розглянемо кожен міф, надаючи у разі потреби додаткові відомості про методологію.
❯ Міф №1. Google не може відрендерити контент, що генерується JS
Цей міф спонукав багатьох розробників уникати використання JS-фреймворків або застосовувати складні обхідні рішення для SEO-завдань.
Щоб перевірити здатність Google обробляти контент, що генерується за допомогою JS, ми зосередилися на кількох ключових аспектах:
- Сумісність з JS-фреймворками: ми проаналізували взаємодію Googlebot з Next.js на основі даних з nextjs.org - сайту, що використовує поєднання попереднього рендерингу статичного контенту, серверного та клієнтського рендерингу.
- Індексування динамічного контенту: ми вивчили сторінки nextjs.org, які завантажують контент асинхронно через дзвінки API. Це дозволило визначити, чи може Googlebot обробляти та індексувати контент, відсутній у початковій HTML-відповіді.
- Поточний контент через React Server Components (RSC): аналогічно до попереднього пункту, значна частина nextjs.org побудована з використанням Next.js App Router і RSC. Ми відстежували, як Googlebot обробляє та індексує контент, що надходить на сторінку поступово.
- Успішність рендерингу: ми порівняли кількість запитів Googlebot у наших серверних логах із кількістю успішних сигналів про завершення рендерингу. Це дало уявлення про частку проіндексованих сторінок, які були повністю відрендеровані.
Висновки
З більш ніж 100 000 запитів Googlebot на nextjs.org (за винятком помилок та неіндексованих сторінок), 100% HTML-сторінок були успішно відрендеровані, включаючи сторінки зі складними JS-взаємодіями.
Весь контент, що завантажується асинхронно через API-дзвінки, був успішно проіндексований, що демонструє здатність Googlebot обробляти контент, що динамічно завантажується.
Фреймворк Next.js, побудований на React, був повністю відрендерований Googlebot, що підтверджує сумісність робота з сучасними JS-фреймворками.
Контент, що надходить потоково через RSC, був повністю отрендерен, що свідчить про відсутність негативного впливу потокової передачі на SEO.
Google намагається відрендерити всі HTML-сторінки, які він бачить, а не лише деякі сторінки з "важким" JS.
Міф №2. Google по-різному обробляє сторінки JS
Поширена помилкова думка, що Google використовує окремий підхід для обробки сторінок із великим обсягом JS. Наші дослідження, а також офіційні заяви Google спростовують цей міф.
Щоб перевірити, чи Google по-різному обробляє сторінки з JS, ми застосували кілька методів:
- Тест із CSS @import: ми створили тестову сторінку без JS, але з CSS-файлом, який підключає (@imports) другий CSS-файл (він буде завантажений і з'явиться в серверних логах тільки при розборі першого CSS-файлу). Порівнявши цю поведінку зі сторінками з JS, ми могли перевірити, чи обробляє Google CSS файли по-різному.
- Обробка кодів стану та мета-тегів: ми розробили Next.js-додаток із проміжним шаром для тестування різних HTTP-кодів стану. Аналіз був зосереджений на тому, як Google обробляє сторінки з різними кодами (200, 304, 3xx, 4xx, 5xx) та з мета-тегами noindex. Це допомогло зрозуміти, чи обробляються сторінки з інтенсивним використанням JS у цих сценаріях по-різному.
- Аналіз складності JS: ми порівняли рендеринг Google на сторінках nextjs.org з різними рівнями складності JS — від мінімального до високодинамічного із великим клієнтським рендерингом. Також розрахували та порівняли час між початковим аналізом та завершеним рендерингом, щоб визначити, чи впливає більш складний JS на тривалість черг рендерингу (rendering queues) чи час обробки.
Висновки
Наш тест із імпортом додаткового файлу CSS підтвердив, що Google успішно рендерить сторінки незалежно від того, чи містять вони JS чи ні.
Google рендерує всі HTML-сторінки з кодом стану 200 незалежно від наявності JS. Сторінки з кодом 304 рендеруються на основі оригінального контенту 200 коду. Сторінки з кодами 3xx, 4xx та 5xx не рендеруються.
Сторінки з мета-тегом noindex у вихідному HTML не рендеруються, незалежно від JS. Видалення тега noindex на клієнтській стороні є неефективним для SEO, оскільки Google не рендерує сторінку, якщо тег присутній у початковій HTML-відповіді.
Ми не виявили суттєвої різниці в ефективності рендерингу Google сторінок із різною складністю JS. На масштабах nextjs.org ми не виявили кореляції між складністю JS та затримкою рендерингу. Однак складніший JS на набагато більшому сайті може погіршувати ефективність індексації.
❯ Міф №3. Черга рендерингу та тимчасові затримки суттєво впливають на SEO
Багато фахівців із SEO вважають, що сторінки з великим обсягом JS стикаються зі значними затримками індексації через чергу рендерингу. Наше дослідження дає чіткіше уявлення про цей процес.
Щоб оцінити вплив черги рендерингу та тимчасових затримок на SEO, ми вивчили такі аспекти:
- Затримки рендерингу: ми проаналізували різницю в часі між початковим аналізом сторінки Google та завершенням її рендерингу, використовуючи дані більш ніж 37 000 сторінок на nextjs.org.
- Типи URL: ми проаналізували час рендерингу для URL-адрес, що містять і не містять рядки запиту (query string), а також для різних розділів nextjs.org (наприклад, /docs, /learn, /showcase).
- Шаблони частоти: ми досліджували, як часто Google повторно рендерує сторінки і чи існують закономірності в частоті рендерингу для різних типів контенту.
Висновки
Розподіл затримок рендерингу виглядає так:
- 50-й процентиль (медіана): 10 секунд.
- 75-й процентиль: 26 секунд
- 90-й процентиль: ~3 години
- 95-й процентиль: ~6 годин
- 99-й процентиль: ~18 годин
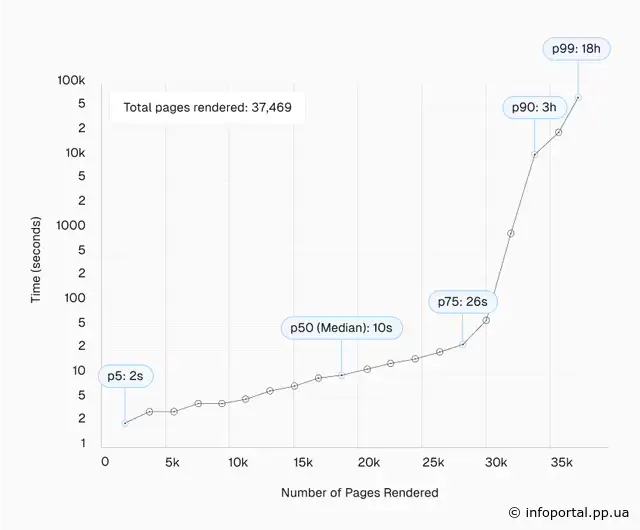
Незважаючи на те, що деякі сторінки стикалися зі значними затримками (до ~18 годин у 99-му процентилі), це були лише винятки.
Більш того, результати дослідження показали, що 25-й процентиль сторінок був відрендерований протягом 4 секунд після початкового аналізу, що ставить під сумнів уявлення про тривалу "чергу" рендерингу.
Ми також спостерігали цікаві закономірності, пов'язані з тим, як швидко Google рендерит URL-адреси з параметрами запиту (?param=xyz):
Ці дані свідчать про те, що Google по-різному обробляє URL-адреси з параметрами запиту, які не впливають на вміст. Так, на nextjs.org сторінки з параметрами ?ref= демонстрували більш тривалі затримки рендерингу, особливо на високих відсотках.
Крім того, ми помітили, що розділи, що часто оновлюються, на кшталт /docs, мали менший медіаний час рендерингу в порівнянні з більш статичними розділами. Наприклад, сторінка /showcase, незважаючи на часті посилання на неї, показувала триваліший час рендерингу, що може вказувати на уповільнення повторного рендерингу Google для статичних сторінок.
❯ Міф №4. Сайти з великою кількістю JS відрізняються повільнішою швидкістю виявлення сторінок пошуковими ботами
Стійка думка у спільноті SEO фахівців: веб-сайти з великим обсягом JS, що особливо використовують клієнтський рендеринг (CSR), такі як односторінкові програми (SPA), стикаються з більш повільним виявленням сторінок пошуковою системою Google. Наші дослідження заперечують цей міф.
Для вивчення впливу JS на виявлення сторінок було проведено деякі тести:
Порівняли швидкість виявлення посилань за різних підходів до рендерингу — серверного, статичного та клієнтського (на прикладі nextjs.org).
Протестували виконання коду JS, який не використовується на сторінці: ми додали на сторінку /showcase JSON-об'єкт, схожий на корисне навантаження React Server Component (RSC), що містить посилання на нові раніше невідомі сторінки, щоб перевірити, чи зможе Google виявляти посилання в JS, що не використовується.
Порівняли час: ми відслідковували, наскільки швидко Google індексує нові сторінки, на які посилалися різними способами: у HTML-посиланнях, у клієнтському рендерингу та в корисному навантаженні JS, яке не використовується.
Висновки
Google однаково успішно знаходить та індексує посилання на повністю відрендерованих сторінках, незалежно від методу рендерингу.
Google здатний знаходити посилання навіть у невідрендерованих даних, таких як корисне навантаження серверних компонентів React.
Як у вихідному, так і у відрендерованому HTML, Google обробляє вміст, визначаючи рядки, схожі на URL-адреси. При цьому він використовує поточний хост та порт як базу для відносних посилань. Варто зазначити, що Google не виявив закодовану URL (https%3A%2F%2Fwebsite.com) у нашому подібному RSC навантаженні, що свідчить про суворий підхід пошуковика до розбору посилань.
Джерело та формат посилання (наприклад, тега <a> або вбудована в JSON-навантаження) не впливають на пріоритет індексування Google. Пріоритет індексування залишався послідовним, незалежно від того, було виявлено посилання при первинному індексуванні або після рендерингу.
Хоча Google ефективно індексує посилання на сторінках з рендерингом клієнтів, сторінки з серверним або частковим рендерингом мають невелику перевагу в швидкості первинного виявлення.
Google розрізняє процеси виявлення посилань та оцінки їхньої цінності для ранжування, остання відбувається після повного рендерингу сторінки.
Наявність актуальної карти сайту (sitemap.xml) значно знижує або усуває відмінності у швидкості індексації між різними підходами до рендерингу.
❯ Загальні висновки та рекомендації
Наші дослідження заперечують кілька поширених міфів про те, як Google взаємодіє з сайтами, що містять велику кількість JS. Ключові висновки та практичні рекомендації є наступними.
Висновки:
- Сумісність з JS: Google ефективно обробляє та індексує JS-контент, включаючи складні односторінкові програми (SPA), контент, що динамічно завантажується, і потокові дані.
- Єдиний підхід до рендерингу: немає принципових відмінностей у тому, як Google обробляє сторінки з великим обсягом JS та статичні HTML-сторінки. Усі вони проходять процес рендерингу.
- Черга рендерингу: хоча черга рендерингу існує, її вплив менш значущий, ніж прийнято вважати. Більшість сторінок обробляються за лічені хвилини, а чи не протягом днів чи тижнів.
- Виявлення сторінок: сайти з великим обсягом JS, включаючи односторінкові програми (SPA), нічого не втрачають у плані їх індексації Google.
- Своєчасність контенту: важливо додавати певні елементи (наприклад, теги noindex) вчасно, оскільки Google може не врахувати зміни, що вносяться на стороні клієнта.
- Визначення цінності посилань: Google розмежовує виявлення посилань та визначення їх цінності, останнє відбувається після повного рендерингу сторінки.
- Приоритизація рендерингу: процес рендерингу Google не суворо підкоряється принципу "першим увійшов - першим вийшов" (first-in-first-out, FIFO). Чинники, такі як "свіжість" контенту та частота оновлень, впливають на пріоритизацію більше, ніж складність JS.
Продуктивність рендерингу та краулінговий бюджет: незважаючи на здатність Google ефективно обробляти сторінки з великим обсягом JS, цей процес потребує більше ресурсів у порівнянні зі статичними HTML-сторінками як з боку власників сайтів, так і з боку самого Google. Для великих сайтів в (10 000+ унікальних сторінок, що часто оновлюються) це може негативно позначатися на бюджеті краулінгу. Оптимізація продуктивності програми та мінімізація надлишкового JS можуть прискорити процес рендерингу, підвищити ефективність аналізу та, як наслідок, дозволити Google індексувати більшу кількість сторінок.
❯ Застосування отриманих знань
Можна відзначити такі відмінності між стратегіями рендерингу в контексті можливостей Google:
* Використання актуальної карти сайту (sitemap.xml) суттєво скорочує або навіть усуває відмінності у часі виявлення між різними моделями рендерингу.
** Згідно з нашими дослідженнями, рендеринг у Google зазвичай проходить без помилок. Коли виникають проблеми, вони зазвичай пов'язані із заблокованими ресурсами, вказаними у файлі robots.txt, або крайніми випадками.
😎 Незважаючи на ці тонкі відмінності, Google швидко виявить і проіндексує ваш сайт, незалежно від стратегії рендерингу, що використовується. Краще зосередитися на створенні продуктивних веб-застосунків, які приносять користь користувачам, замість того, щоб турбуватися про особливості індексації Google.
🙄 Зрештою, швидкість завантаження сторінки, як і раніше, є фактором ранжування, оскільки система ранжування досвіду користувача Google оцінює продуктивність вашого сайту на основі показників Core Web Vitals.
😃 Крім того, швидкість завантаження програми безпосередньо пов'язана з хорошим досвідом користувача - кожні 100 мс зекономленого часу завантаження відповідають 8% зростання конверсії на сайті. Найменша кількість користувачів, що залишають сторінку, означає, що Google розглядає її як більш релевантну. Продуктивність має мультиплікативний ефект; мілісекунди важливі.
Схожі новини: